|
|
|
 | |
 |
Convera RetrievalWare 7.0.
Convera RetrievalWare 7.0. - промышленная информационно-поисковая система, представляющая собой мощное средство полнотекстового и атрибутивного поиска.RetrievalWare 7.0. позволяет быстро находить и получать документы, используя в качестве клиентского места обычный web-браузер (например, Microsoft Internet Explorer или Netscape Navigator/Communicator).
К документам, с которыми работает RetrievalWare7.0. относятся тексты в различных форматах и кодировках, электронные таблицы, базы данных, почтовые сообщения и т.п. - всего более 250 форматов плюс инструментарий, позволяющий без затрат на программирование настроить систему на поддержку специфических форматов документов заказчика. Объем архива при этом может измеряться терабайтами, время же поиска очень мало, и при увеличении объема библиотеки растет нелинейно.
Архитектура RW 7.0. позволяет работать с системой как через корпоративную локальную сеть, так и через Internet.
Серверная часть системы может быть установлена на всех распространенных серверных платформах, а клиентским местом может быть любая машина, имеющая графический Web-браузер. Система может также работать в различных многопроцессорных и распределенных многосерверных конфигурациях - что повышает ее эффективность и надежность при работе с большими объемами информации.
Источником информации может быть файловая система, системы управления базами данных (MS SQL, ORACLE, Sybase, Informix и пр. ODBC-совместимые СУБД), почтовые системы (Microsoft Exchange, Lotus Notes и т.п.), системы управления документами (Documentum EDMS, FileNET Panagon и т.п.), узлы корпоративной intranet-сети и Internet, а также электронный архив Convera FileRoom. - средство организации доступа к бумажным документам; не представляет труда и поддержка нестандартных источников документов.
С помощью так называемых синхронизаторов система практически мгновенно реагирует на добавление, удаление и изменение документов. Возможно наследование системой прав доступа к документу от источника, из которого он поступил - и авторизация через этот источник.
RetrievalWare 7.0. способен эффективно работать с большими (и постоянно растущими) объемами разнородной текстовой информации. Этому способствуют, в частности мощные поисковые возможности RetrievalWare, базирующиеся на оригинальных разработках Convera Technologies Corp.
Родившаяся в процессе моделирования сложных биологических систем, технология адаптивного распознавания образов APRP (Adaptive Pattern Recognition Processing) использует нейронные сети для обработки информации и действует как самоорганизующаяся система, которая автоматически выделяет в массиве хранимой информации и индексирует двоичные образы.
Уникальные возможности технологии адаптивного распознавания образов обеспечивают семейству программных продуктов RetrievalWare (Visual RetrievalWare, Screening Room) преимущества при построении поисковых приложений фактически для любой информации, представленной в электронном виде - текстов, изображений, звуков, видеоинформации.
К преимуществам применения технологии адаптивного распознавания образов APRP для поиска текстовой информации можно отнести нечеткий поиск, высокую точность и полноту поиска, языковую независимость, малые объемы индексных файлов.
Нечеткий поиск, основанный не на поиске точных совпадений слов документа с словами запроса, а на исчислении их меры близости, позволяет исключить из цикла обработки бумажных документов дорогостоящий этап ручного исправления ошибок оптического распознавания символов.
Если технология адаптивного распознавания образов APRP повышает эффективность работы с любой информацией, то технология семантического поиска ориентирована на работу со знаниями, содержащимися в текстовых документах.
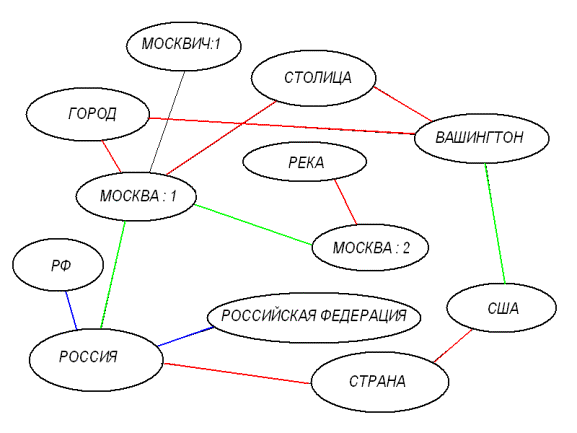
Основой технологии семантического поиска является использование семантических сетей (см. рис. 1), описывающих смысл слов языка и связи между обозначаемыми ими понятиями (следует заметить, что в данном случае термин "семантическая сеть" используется в том смысле, какой в него вкладывает компания Convera - то есть речь идет о тезаурусе, позволяющем, однако, не только найти слова, связанные по смыслу с данным, но и определить количественно "семантическое расстояние между ними").
Профессионально реализованная поддержка русской морфологии также повышает эффективность поиска.
Семантическая сеть словаря русского языка включает в себя около 40 тысяч семантических групп в базовом варианте поставки (однако существуют и другие варианты поставки; возможно и подключение лингвистических ресурсов сторонних разработчиков). Использование семантической сети позволяет пользователю просто ввести поисковый запрос на естественном языке, предоставив системе самой искать все документы, контекст которых совпадает с контекстом запроса. Используемые технологии позволяют распознать слово в любой грамматической форме. Для слов, имеющих несколько значений, пользователь может уточнить, какие именно значения он имеет в виду.
Технология семантического поиска позволяет также использовать одновременно несколько словарей. Например, одновременно с базовым словарем, система может использовать отраслевой словарь, внутренний словарь организации и даже личный словарь пользователя, которые могут разрабатываться по мере необходимости. Семантическая сеть применяется на двух этапах поиска. Во первых, после ввода запроса, входящие в него слова дополняются связанными с ними по смыслу словами (синонимами, вариантами написания, аббревиатурами и т.п.). Это позволяет находить и те документы, в которых фигурирующая в запросе идея выражена по-другому (например, слово "РОССИЯ" будет расширено словами "РОССИЙСКАЯ ФЕДЕРАЦИЯ", "РФ" и т.д.).
Вторым этапом поиска, на котором используется семантическая сеть, является упорядочивание найденных документов по степени соответствия запросу. Применение семантики позволяет учитывать общий контекст документа.
При работе с текстами на разных языках, семантические сети RetrievalWare позволяют организовать многоязычный поиск в обоих смыслах - то есть как multy-language search (возможность использовать разные языки в одном запросе и указывать язык в явном виде), так и cross-language search (словарный перевод запроса на все языки, документы на которых есть в системе). В настоящий момент в RetrievalWare есть поддержка следующих языков: русского, английского, французского, немецкого, испанского, китайского (как для упрощенной, так и для традиционной кодировки), голландского, японского, португальского, корейского, итальянского, арабского. Ведутся работы по поддержке украинского языка.
Помимо вышеперечисленного, RW 7.0. обладает развитым языком построения поисковых запросом, включающим в себя логические и контекстные операторы. Существует и возможность поиска документов по образцу (query by example) - при этом система сама выбирает из документа наиболее статистически и семантически значимые слова и формирует из них сложный логический запрос, учитывающий и структуру, и смысловое содержание документа.
Все запросы (а их объем в сложных случаях может измеряться килобайтами) могут быть сохранены в базе данных для последующего редактирования и повторного использования. На их основе может быть построен рубрикатор.
Результаты поиска отображаются в виде списка найденных документов. По умолчанию список отсортирован по релевантности, однако может быть задан любой другой критерий сортировки (по значению атрибутов, по времени добавления в индекс и т.п.) - в том числе и составной. Отчет может быть иерархически сгруппирован по атрибутам документов (соответственно, при группировке отчета по атрибуту "Источник" отчет представляет собой дерево, первый уровень которого содержит список всех источников, к которым принадлежат найденные документы, а второй - сами документы).
В настоящее время ведутся работы по созданию модуля кластеризации и визуализации результатов поиска.
Модульная структура RetrievalWare позволяет настраивать эту систему на решение стоящей перед пользователем задачи. Ниже будут описаны некоторые модули системы, расширяющие ее функциональные возможности.
Если за сутки в архив добавляется значительное количество документов, пользователю может быть нелегко отслеживать изменения в интересующей его области. Решению этой задачи призван помочь сервер рубрикации RetrievalWare. По мере поступления документов он распределяет их по тематическим рубрикам (категориям) в соответствии с ранее введенными запросами. При этом один документ может входить в несколько рубрик. В дальнейшем рубрики могут использоваться для ограничения зоны действия поискового запроса - формируя тем самым логическую структуру хранилища документов.
Система позволяет подключать и внешние средства рубрикации и кластеризации поступающих документов.